Exploring Twitter's Potential for Location-Based Insights
Written on
Chapter 1: Understanding Twitter's Location Data
With over 500 million tweets posted daily, can we effectively track patterns in social movements?

The platform Twitter serves as a remarkable repository of data, containing valuable insights about public sentiments. Research has even indicated that aggregated tweet data can serve as an indicator of societal well-being! Given its concise character limit and widespread usage, Twitter is ideally suited to reflect public opinions.
In addition to the textual information, tweets often come with critical location data. A subset of users opts to share their tweet locations with Twitter, which adds another dimension to the analysis. In the future, incorporating real-time data layers—such as traffic, incidents, and smart city signals—could significantly enhance our ability to monitor the complexities of modern society.
My primary aim in composing this article was to extract location data from tweets and assess how representative this data is of various populations. If tweets serve as a mirror of societal trends or consumer behavior, it's essential that they reflect diverse socioeconomic backgrounds. This would involve comparing tweet distributions with census data. Unfortunately, I have only made partial progress toward this goal, largely due to a limited number of users who agree to share their precise locations, coupled with Twitter's assignment of coordinates based on tweet content.
Section 1.1: Utilizing Tweepy for Location Extraction
Tweepy is a Python library that acts as a wrapper for the Twitter API. Let’s begin by loading the necessary packages in Python:
import sys
import os
import re
import tweepy
from tweepy import OAuthHandler
from textblob import TextBlob
import numpy as np
import pandas as pd
from datetime import datetime, timedelta
from IPython.display import clear_output
import matplotlib.pyplot as plt
% matplotlib inline
Next, we will authenticate the user credentials using Tweepy.
# Authenticate
auth = tweepy.AppAuthHandler(consumer_key, consumer_secret)
api = tweepy.API(auth, wait_on_rate_limit=True, wait_on_rate_limit_notify=True)
if not api:
print("Authentication failed")
sys.exit(-1)
Now, we will filter tweets from a specific location. Twitter provides several methods for this—either by using a bounding box of up to 25 miles or by specifying a location with a maximum radius of 25 miles.
tweet_lst = []
geoc = "38.9072,-77.0369,1mi"
for tweet in tweepy.Cursor(api.search, geocode=geoc).items(1000):
tweetDate = tweet.created_at.date()
if tweet.coordinates is not None:
tweet_lst.append([tweetDate, tweet.id, tweet.coordinates['coordinates'][0],
tweet.coordinates['coordinates'][1], tweet.user.screen_name,
tweet.user.name, tweet.text, tweet.user._json['geo_enabled']])
tweet_df = pd.DataFrame(tweet_lst, columns=['tweet_dt', 'id', 'lat', 'long', 'username', 'name', 'tweet', 'geo'])
Using the Tweepy Cursor object, which handles Twitter's pagination limit of 100 results per page, I restricted the data to 1,000 tweets within a one-mile radius of downtown Washington, DC, specifically focusing on tweets with latitude and longitude information.
Section 1.2: Analyzing the Location Data
From the 1,000 tweets collected, 714 contained unique location data. Let’s delve deeper into this information.
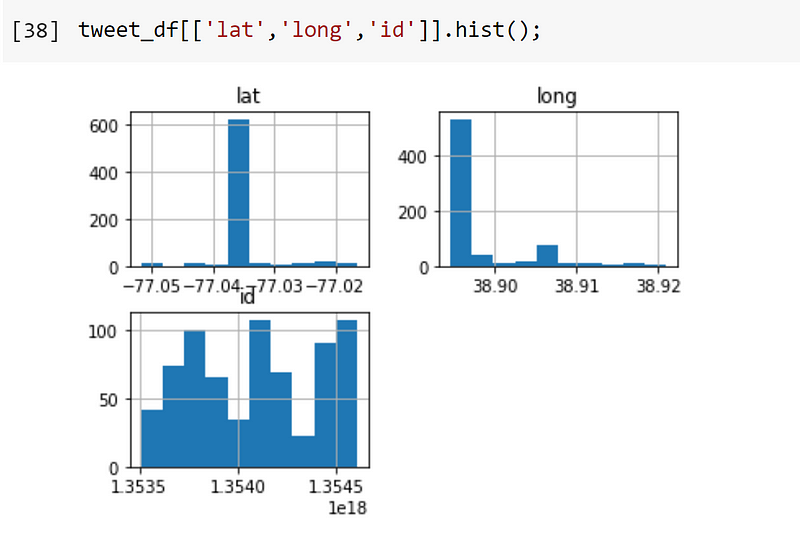
Interestingly, there are only 80 distinct latitude/longitude pairs, although each tweet and user ID is unique. This discrepancy suggests an anomaly, as it seems unlikely that so many users are concentrated in the same spot. Here’s a filtered view of the most frequently occurring latitude/longitude pair:
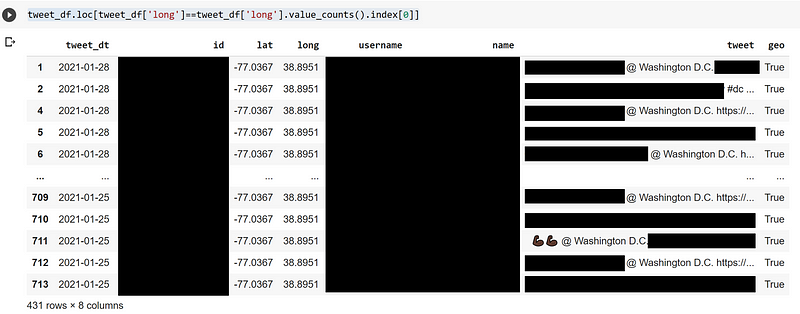
As you can see, many tweets contain references to @WashingtonDC, leading Twitter to default to this central location for any tweet mentioning it.
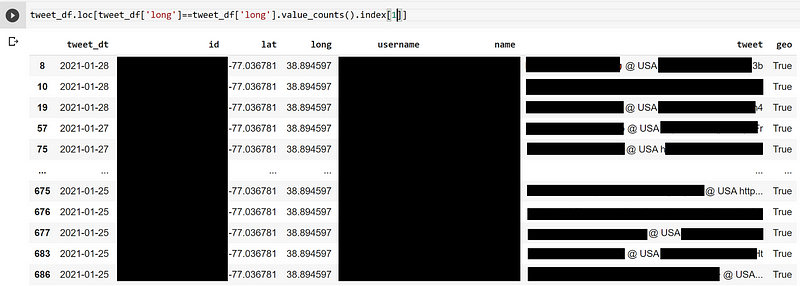
When examining the second most common location, I found that references included @USA, which is defined by Twitter as a location just south of the White House, situated in a park!
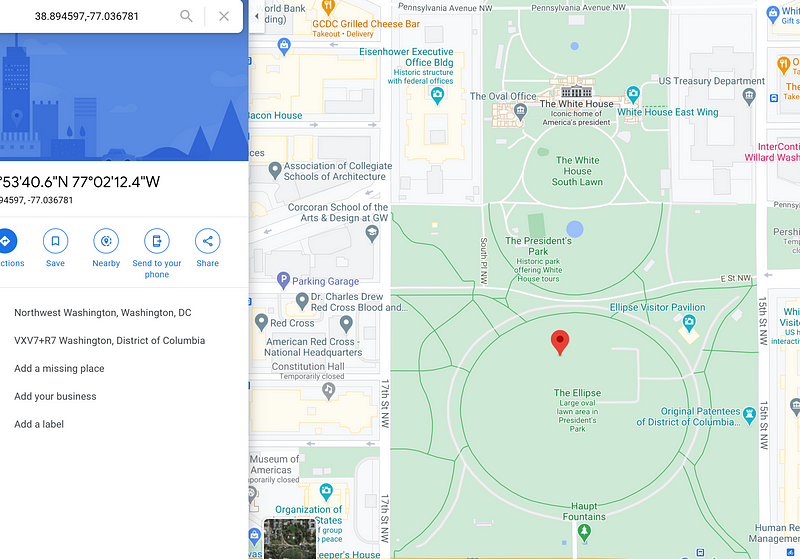
Upon reviewing Twitter’s documentation:

While I seek the geographical coordinates of sample users for aggregate mobility analysis, Twitter provides location tags that often reflect popular spots rather than the actual locations of tweet authors. During a broader search extending to a 25-mile radius, I found zero tweets with coordinate information, likely due to Twitter's tendency to assign coordinates based on well-known locations in DC.
Here’s a link to the Google Colab notebook detailing the code:
Google Colaboratory
Twitter-Geospatial
colab.research.google.com
Chapter 2: The Challenges of Geospatial Analysis
In conclusion, Twitter holds immense potential for analyzing societal trends, including sentiments and mobility patterns. However, challenges arise in geospatial analysis due to sparse data and the ambiguity of location meanings—whether they denote the actual position of the device or simply references made in tweets.
While improvements to the Twitter API could be beneficial, privacy concerns regarding the mass sharing of sensitive location information must also be addressed. Personally, I would be open to sharing my location data for large-scale analyses that could benefit society, but I hesitate due to potential risks. We find ourselves at a pivotal moment, akin to the early days of nuclear energy. While detailed data has the capacity to bring about significant societal benefits, we must engage in ongoing discussions to maximize these advantages while safeguarding against data breaches and misuse.
If you found this article insightful, consider following me for more content at the intersection of complex systems, physics, data science, and society.
Exploring how to scrape tweets based on countries, cities, and places can reveal valuable insights into location-specific social dynamics.
Learn the methods to download and analyze data from Twitter and Facebook, enhancing your understanding of social media analytics.