Understanding Binary Trees and Prefix Trees: A Comprehensive Overview
Written on
Chapter 1: The Basics of Tree Structures
Trees are a fundamental concept in Computer Science that many programmers encounter, especially when dealing with Binary Search Trees. Unlike natural trees, in the computing world, these structures are inverted, with the root positioned at the top, leading to initial confusion.
To clear up this complexity, let's break down Binary Trees.
Binary Tree Overview
A Binary Tree is a data structure designed to organize data efficiently, allowing for quicker searches while minimizing space utilization.
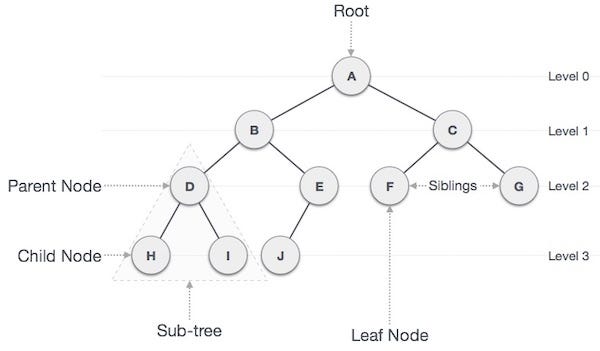
Key Definitions:
- Node: A point within the tree that contains data.
- Root: The top node of the tree, of which there can only be one.
- Leaf: A node that has no children.
- Height: The longest path of edges from a leaf to the root.
- Traversal: The process of moving through the tree.
- Parent: A node that has at least one child below it.
- Child: A node that is beneath another node.
Each node in a Binary Tree contains its own data and pointers to its left and right children, which is crucial for traversing the tree.
The efficiency of Binary Trees lies in their structure. When inserting data, values less than the current node go to the left, while greater values go to the right. This organization leads to a time complexity of O(n). However, if the tree becomes unbalanced, where one side has significantly more data than the other, it can slow down searches, necessitating traversal through each node.
AVL Trees: A Balanced Approach
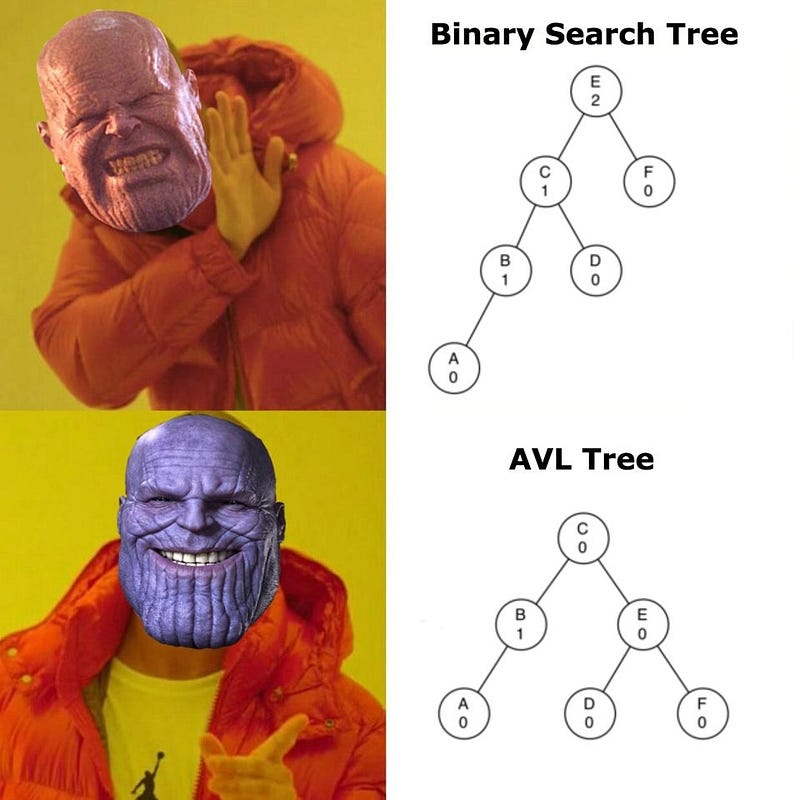
To address the issue of unbalanced trees, we have the AVL Tree, named after its creators, Adelson-Velsky and Landis. This self-balancing tree operates like a seesaw, ensuring that weight is evenly distributed. When an imbalance occurs, the tree repositions nodes through left and right rotations to restore balance.
By maintaining balance, AVL Trees improve the time complexity to O(log n), significantly enhancing search efficiency.
Chapter 2: Prefix Trees (Tries)
Similar to Binary Trees are Prefix Trees, commonly known as Tries. We encounter this structure frequently in everyday applications like texting and search engines that use autocomplete features.
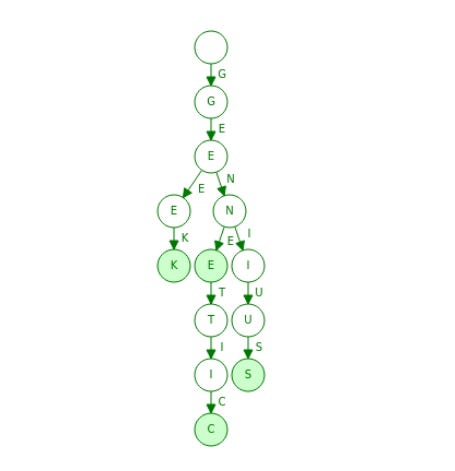
Tries excel at storing strings or sets of characters. Each Trie node holds a character and pointers to subsequent nodes. Unlike Binary Trees that utilize numerical keys, Tries use letters for traversal, as depicted by the letters connecting the nodes. For example, following the leftmost path reveals "GEEK," the middle path leads to "GENETICS," and the rightmost one results in "GENIUS."
A key feature of Tries is that child nodes can accommodate up to 26 entries, corresponding to the 26 letters in the English alphabet. This makes them suitable for various applications, including data science tasks and word puzzles.
Conclusion: A Future in Tree Structures
While there are many types of trees, this overview focuses on Binary Trees and Prefix Trees, laying the groundwork for deeper exploration into their implementation. Understanding these structures is essential for optimizing computer science applications, leading to the development of faster and more efficient software.
Take note: mastering these tree structures is crucial for building applications that are both efficient and resource-conscious.