Understanding Consistent Hashing in Distributed Systems
Written on
Chapter 1: Introduction to Consistent Hashing
Consistent hashing is fundamental to numerous distributed systems. This hashing approach addresses the challenges of data distribution and locality while minimizing system disruption. In this article, we’ll explore the mechanics of consistent hashing and its application in constructing distributed systems.
For illustrative purposes, we will design a system that requires the data of each user to be stored together in a distributed setup. We’ll utilize the username as the key for hashing.
Section 1.1: Splitting Data with Hashing
In a distributed environment, data is typically divided among various nodes or servers. For instance, if we have two servers, it would be ideal for 50% of users to be allocated to the first server and the other 50% to the second.
To achieve this division, one straightforward method is to use the usernames for distribution. Users with usernames beginning with letters A through M can be assigned to Node 1, while those starting with letters N through Z can go to Node 2. If we had three servers, we could extend this method by using the first character of the username to allocate users accordingly.
However, this method poses a challenge: many usernames may begin with certain letters, resulting in an uneven distribution across the servers. To overcome this, we need a strategy that ensures uniform data allocation.
A viable solution is to employ a hashing algorithm that generates a random and uniform distribution. We begin by mapping usernames to numerical values, which will serve as fixed hash buckets. This approach allows us to categorize millions of users consistently across any number of buckets, whether that's 100, 1000, or even 1 million. Consequently, once a user is assigned to a specific bucket, they will always remain there. A well-designed hash function guarantees this uniform distribution.
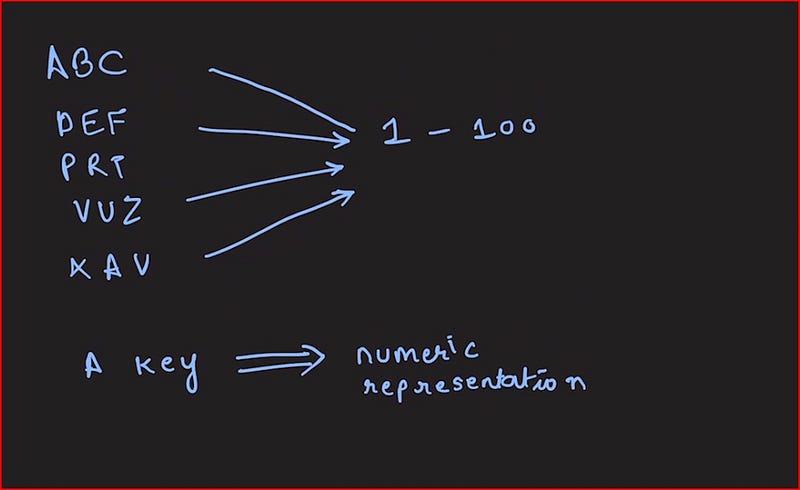
With two servers, for example, we can allocate hash values from 0-49 to the first server and 50-99 to the second. This strategy ensures a balanced allocation of keys throughout the cluster.
Section 1.2: Addressing Additional Challenges
Although this method improves data distribution, it introduces a new challenge: what occurs when a new server is added to our two-server setup? In accordance with our hashing strategy, server 1 would manage hash values from 0-33, server 2 would cover 34-67, and the new server would take on hashes between 68-99.
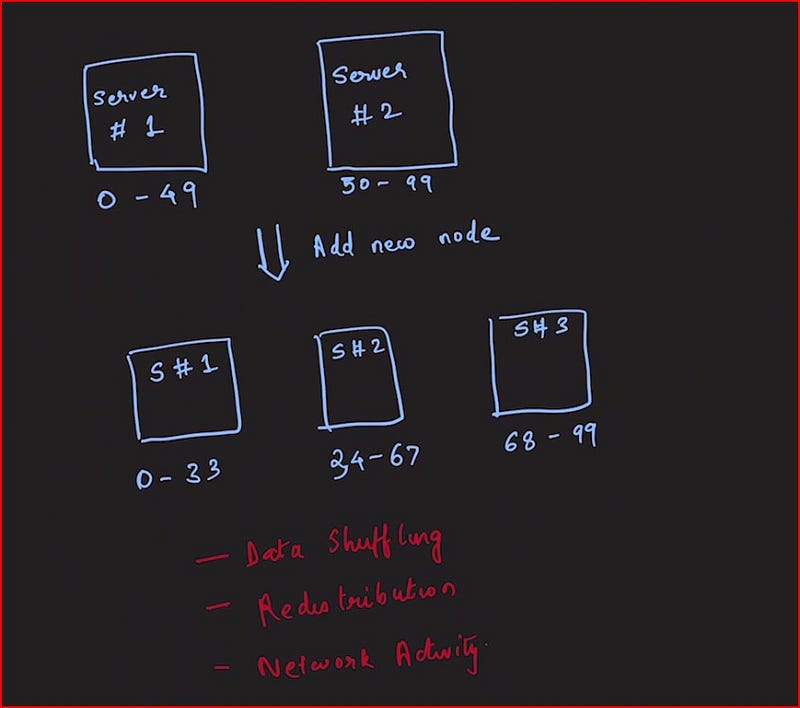
The issue with this setup is that every time a new node is integrated or removed, we must redistribute hashes across all machines. If we had 20 nodes, this redistribution could lead to significant overhead.
To mitigate this, we need a method to minimize hash redistribution. This is where consistent hashing becomes advantageous.
Chapter 2: The Concept of Consistent Hashing
Consistent hashing refines the previous hashing technique by aiming to minimize data movement when server loads fluctuate. It allows us to efficiently identify which node to query for specific data.
The core idea behind consistent hashing is to conceptualize a virtual space where all keys are mapped. Imagine a circular structure with hash slots numbered from 0 to n-1, where n represents the number of hashing buckets. When we hash keys using our algorithm, all keys (like user IDs) will be positioned at various points along the ring.
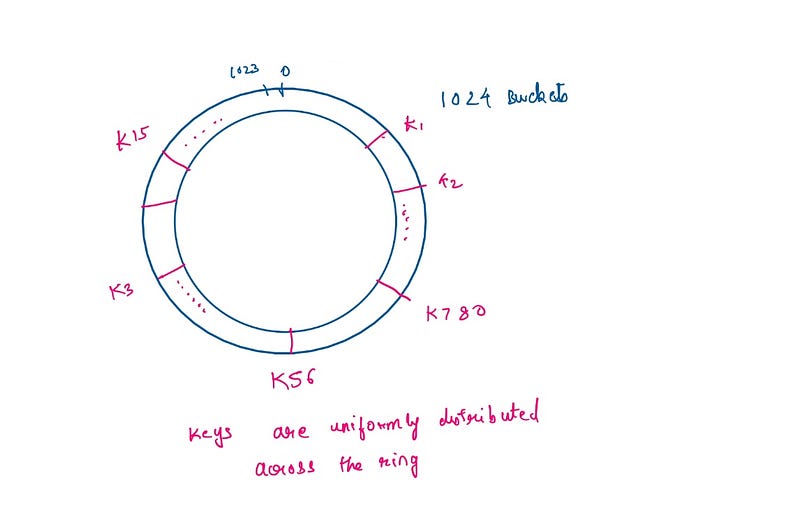
In this example, we have designated 1024 buckets. Regardless of whether we have millions of keys, they can be uniformly spread across these buckets.
To ensure balanced distribution across the machines in our cluster, we hash the machine IDs on the same ring. Let’s consider a scenario with four machines in our cluster. By treating the machine ID as another identifier in the hashing space, we ensure that machine IDs are similarly distributed around the ring.
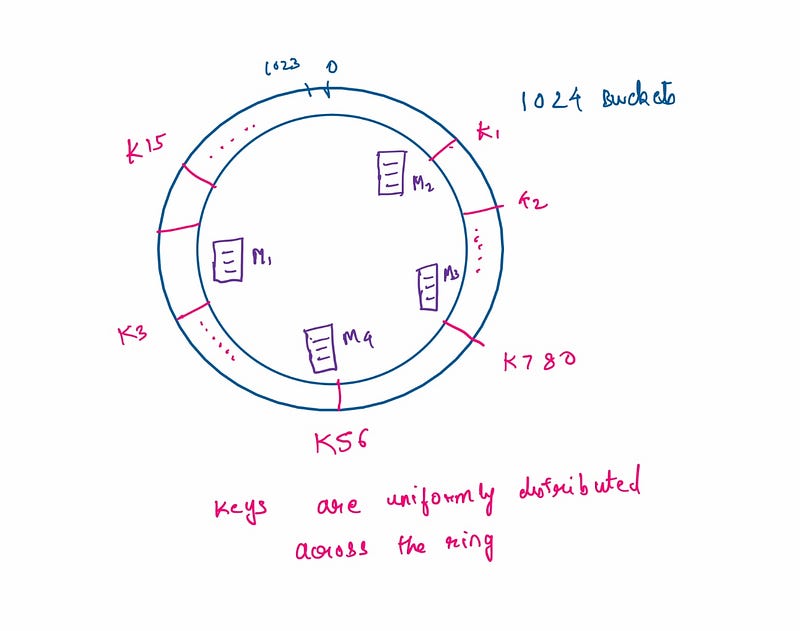
The final step of consistent hashing involves assigning keys to machines.
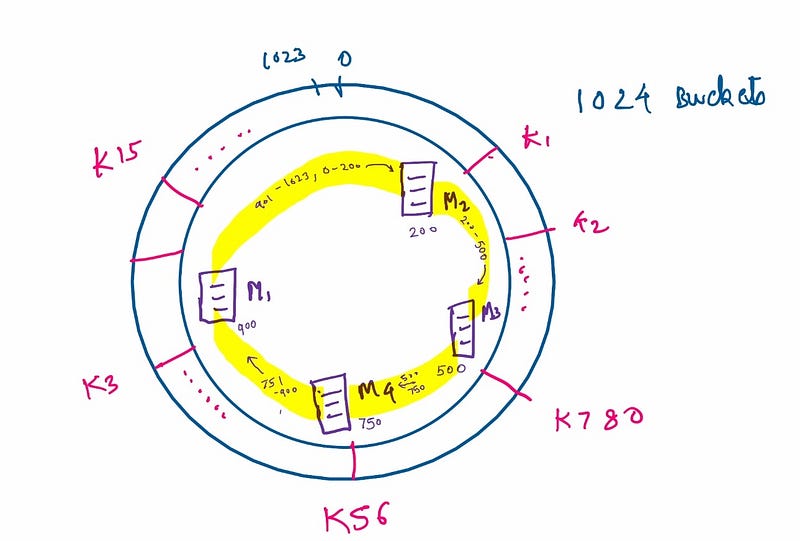
As depicted, we allocate all buckets between two nodes to the subsequent node. Therefore, a key hashed to a specific bucket will consistently be assigned to the next machine on the ring. In this scenario, M2 handles requests for hashes ranging from 901 to 1023 and 0 to 200, while M3 manages keys with hash values between 201 and 500, and so forth.
Section 2.1: Adapting to Node Changes
Since the machines and keys occupy the same hash space, adding or removing a node becomes straightforward. For instance, let's introduce a new machine, M5, positioned between M1 and M2. Observe the changes in data distribution following this adjustment.
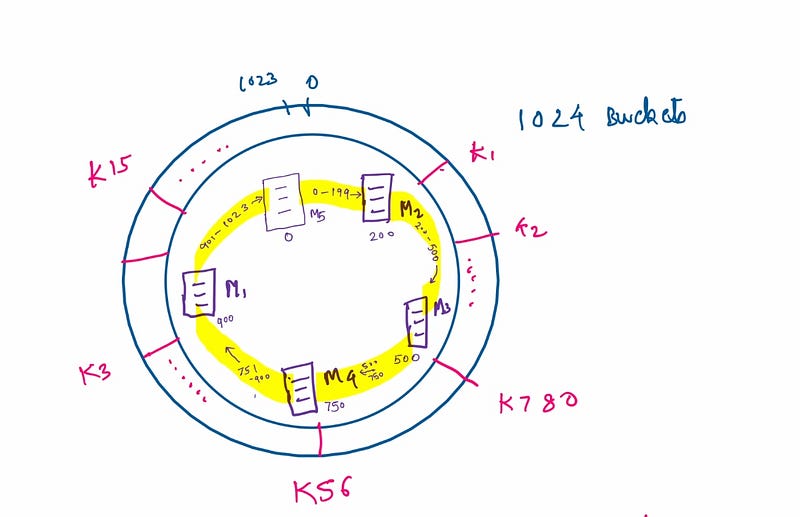
Previously, M2 was responsible for hashes ranging from 901 to 1023 and 0 to 200. With the addition of the new node, it will now manage hashes from 0 to 200, while M5 will take over the range from 901 to 1023. Notably, this transition does not affect the other machines, demonstrating the efficiency of consistent hashing.
When M5 assumes responsibility for the range 901 to 1023, it can simply request this data from M2, resulting in minimal data movement.
Consistent hashing is a powerful technique for distributing data and reducing movement when nodes are added or removed. However, one challenge we haven't addressed is the potential for uneven load distribution among machines. We will explore this topic in a future article.
Understanding distributed systems is greatly aided by comprehending consistent hashing, which illustrates how to evenly distribute data. This foundational knowledge can provide insights into the operations of many real-world systems.
I hope this article clarifies the basics of this technique and offers valuable insights into its implementation in actual systems. Stay tuned for more updates!
The first video titled "Consistent Hash Distributions Explained" delves into the principles of consistent hashing, showcasing how it resolves data distribution challenges in distributed systems.
The second video, "Consistent Hashing Basics Explained Simply," provides an easy-to-understand overview of the consistent hashing concept, making it accessible for beginners.